Learning Objectives
By the end of this chapter, students will be able to:
-
Design a multi-phase remediation plan that ingests findings from all HYDRA pipeline streams and generates dependency-ordered actions.
-
Implement a Pareto frontier multi-objective optimizer that balances risk reduction, cost, and time-to-completion.
-
Describe the seven-stage safety pipeline (risk classification, simulation, postcondition verification, approval, checkpointed execution, health check, and conditional rollback) and explain why each stage is necessary.
-
Generate micro-segmentation policies for IoT/OT networks with export to six vendor formats (iptables, pf, Cisco ACL, Palo Alto XML, AWS Security Groups, Azure NSG).
-
Evaluate automated control-alignment checks against IEC 62443, NIST 800-82, and EU Cyber Resilience Act frameworks.
-
Implement rollback checkpoints and causal remediation graphs for safe, reversible remediation.
-
Design a self-healing network policy monitor that detects configuration drift and auto-reapplies segmentation rules.
Agentic Lens
This chapter introduces the final agent challenge for the course. The agent brings together all the analysis done so far, decides what changes are needed and in what order, gets the right approvals, and gathers the evidence needed to keep the system safe.
-
Agent role. Plan and safely orchestrate remediation actions across the network.
-
Observations. Vulnerability findings, attack paths, twin outputs, compliance gaps, asset criticality, and approval constraints.
-
Tools. Plan generation, optimization, simulation, policy generation, health checks, rollback, and evidence packaging.
-
State. Action dependency graph, checkpoints, risk class, approval mode, execution history, and health signals.
-
Verifier. Twin simulation, postcondition checks, live health checks, compliance deltas, and rollback validation.
-
Guardrails. Reducing risk in one area should never come at the expense of overall system safety. Any action with major consequences must be escalated for review, no matter how confident the planner is.
-
Failure mode worth teaching. If an agent prioritizes plan optimization over system optimization, it may generate a remediation schedule that ultimately disrupts operations.
Threat Model and Assumptions
This chapter treats autonomous remediation as a high-stakes control problem. Every decision can shift the balance between keeping the system safe and causing disruption.
-
Threat model. The adversary benefits from every delay in remediation, but the defender can also damage the network through rushed or poorly verified changes.
-
Threat model. External compromise is only one hazard. The more immediate failure mode is an internally generated outage, lockout, or unsafe state caused by a confident but brittle remediation plan.
-
Assumption. The planner inherits findings, risk signals, twin outputs, approvals, and health telemetry from earlier chapters. If those inputs are incomplete, the plan can be systematically mis-prioritized.
-
Assumption. Optimization weights for cost, time, and risk reduction are governance choices. They are not objective scientific constants.
-
Assumption. Automatic execution is appropriate only for narrow, low-consequence action classes with strong postcondition checks and reliable rollback.
-
Scope boundary. Lower modeled risk does not automatically mean safe execution. True safety still relies on verification, approval, health monitoring, and the ability to reverse changes.
Caution: The techniques described in this chapter have operational boundaries. Always verify assumptions against the specific deployment environment before relying on any automated output.
12.1 Introduction: Closing the Loop
Chapters 1 through 11 covered discovery, analysis, and verification, building a complete list of network issues like urgent CVEs, default credentials, protocol flaws, attack paths, and compliance gaps. But just listing these problems, without taking action, only records the risks without reducing them.
Chapter 12 brings everything together by combining findings from earlier chapters—like CVE assessments, penetration tests, attack paths, protocol verification failures, quantum readiness gaps, deception alerts, supply chain issues, and formal verification problems—to create a prioritized remediation plan that respects dependencies. Each action is tested in the digital twin (see Chapter 6), checked against expected results, and goes through an approval process. The main rule is layered safety: nothing moves forward without being simulated, verified, and approved. For example, a firmware update that could affect other devices is caught in the twin simulation before it reaches production. If rotating credentials could lock out the building management system, the health checker quickly flags the problem.
Evidence label: Illustrative. Method note: The analyst readout serves as a teaching example derived from the remediation workflow, rather than a real-world benchmark. Assumptions: Plan size, action mix, and rollback events correspond to the chapter planner and digital twin. Boundary: This should not be interpreted as a guaranteed remediation profile for operational environments.
12.2 Remediation Plan Generation
12.2.1 Finding Ingestion
The RemediationPlanEngine consumes findings from all HYDRA phases via a unified findings dictionary:
# From apps/api/app/scanning/remediation/plan_engine.py
def generate_plan(self, scan_id, hosts, findings):
steps = []
steps.extend(self._generate_credential_actions(hosts))
steps.extend(self._generate_firmware_actions(hosts))
steps.extend(self._generate_segmentation_actions(hosts))
steps.extend(self._generate_cert_rotation_actions(hosts))
steps.extend(self._generate_config_actions(hosts, findings))
steps.extend(self._generate_cve_actions(findings.get("cves", [])))
steps.extend(self._generate_pentest_actions(findings.get("pentest", [])))
steps.extend(self._generate_attack_path_actions(findings.get("attack_paths", [])))
steps.extend(self._generate_protocol_actions(findings.get("protocol", [])))
steps.extend(self._generate_quantum_actions(findings.get("quantum", [])))
steps.extend(self._generate_deception_actions(findings.get("deception", [])))
steps.extend(self._generate_formal_actions(findings.get("formal", [])))
steps.extend(self._generate_supply_chain_actions(findings.get("supply_chain", [])))
# Prioritize and order
steps = self.prioritize_by_risk(steps)
dep_graph = self.build_dependency_graph(steps)
return RemediationPlan(steps=steps, ...)
Each finding category maps to a specific remediation action type:
| Finding Source | Action Type | Priority | Risk Reduction |
|---|---|---|---|
| Default credentials | Credential rotation | 1 (critical) | 8.0 per device |
| Outdated firmware | Firmware update | 3 | 5.0 per device |
| Device classification (IoT/OT) | Segmentation | 4 | 6.0 per zone |
| CVE (CVSS >= 9.0) | Config change/patch | 1 (critical) | CVSS score |
| CVE (CVSS 7.0-8.9) | Config change/patch | 2 (high) | CVSS score |
| Pentest confirmed exploit | Config change | 1-6 (by severity) | 2.0-9.0 |
| Attack path | Segmentation (break at midpoint) | 3 | 5.0 |
| Protocol vulnerability | Config change | 2-5 | 1.5-8.0 |
| Quantum-vulnerable cipher | Config change | 6 | 3.0 |
| Deception alert (attacker IP) | Segmentation (isolate host) | 1 (critical) | 9.0 |
| Formal verification failure | Config change | 3 | 5.0 |
| Supply chain issue | Config change | 2-5 | 3.0-6.0 |
Evidence label: Illustrative. Method note: the “risk reduction” numbers in this table are normalized planning weights used to rank unlike actions inside one planner. Assumptions: one normalized scale is acceptable for comparative prioritization. Boundary: they are not actuarial loss estimates and do not imply that a credential rotation always reduces real-world risk by exactly 8.0.
12.2.2 Priority Ordering
Steps are sorted by risk-reduction-to-cost ratio (descending). This ensures that the highest-impact, lowest-cost actions are executed first:
def prioritize_by_risk(self, steps):
def _sort_key(step):
cost = step.estimated_cost if step.estimated_cost > 0 else 0.01
ratio = step.risk_reduction / cost
return (-ratio, -step.risk_reduction)
return sorted(steps, key=_sort_key)
A credential rotation (risk_reduction=8.0, cost=0.5) has a ratio of 16.0. A firmware update (risk_reduction=5.0, cost=2.0) has a ratio of 2.5. The credential rotation executes first.
12.2.3 Dependency Graph
Some actions have dependencies. A firmware update may depend on a prior credential rotation (to authenticate to the device). The build_dependency_graph() method constructs an adjacency list from step dependencies and validates that all referenced dependencies exist.
graph TD
A[Rotate Credentials 192.168.1.10] --> B[Firmware Update 192.168.1.10]
A --> C[Disable Telnet 192.168.1.10]
D[Isolate Attacker 10.0.0.5] --> E[Rescan Subnet]
F[Segmentation: IoT Zone] --> G[Certificate Rotation]
style A fill:#ffcdd2
style D fill:#ffcdd2
style F fill:#e1f5fe
12.3 Architecture: The Safety Pipeline
graph TD
A[Remediation Plan] --> B[Risk Classification]
B --> C[Digital Twin Simulation]
C --> D{Cascading Failures?}
D -->|Yes| E[BLOCKED: Plan Cancelled]
D -->|No| F[Postcondition Verification]
F --> G{All Checks Pass?}
G -->|No| H[BLOCKED: Verification Failed]
G -->|Yes| I[Approval Gate]
I --> J{Approved?}
J -->|No| K[REJECTED]
J -->|Yes| L[Execute with Checkpoints]
L --> M[Health Check]
M --> N{All Healthy?}
N -->|No| O[Rollback]
N -->|Yes| P[COMPLETED]
style E fill:#ffcdd2
style H fill:#ffcdd2
style K fill:#fff9c4
style O fill:#fff3e0
style P fill:#c8e6c9
The safety pipeline acts as a safeguard to make sure no remediation step causes unexpected problems. It has seven stages that run in order. If anything fails between stages 2 and 4, the plan stops before any real-world changes are made.
12.4 Multi-Objective Optimization
12.4.1 The Pareto Frontier
Remediation planning is a multi-objective optimization problem with three competing objectives:
-
Maximize risk reduction – close the most critical vulnerabilities first.
-
Minimise cost – budget constraints limit the number of simultaneous changes.
-
Minimise time – some actions take minutes (credential rotation), others take hours (firmware update).
No single plan optimises all three objectives simultaneously. The compute_pareto_frontier() method finds the set of non-dominated solutions – plans that are not dominated by any other plan on all three objectives. In the current implementation, the search is intentionally bounded to the leading candidate actions rather than the full action universe.
# From apps/api/app/scanning/remediation/plan_engine.py
def compute_pareto_frontier(self, steps):
candidates = steps[:20]
solutions = []
# Singles and pairs
for s in candidates:
solutions.append([s])
for i, s1 in enumerate(candidates):
for s2 in candidates[i + 1:]:
solutions.append([s1, s2])
# Filter dominated solutions
frontier = []
for i, (r1, c1, t1, s1) in enumerate(evaluated):
dominated = False
for j, (r2, c2, t2, _) in enumerate(evaluated):
if r2 >= r1 and c2 <= c1 and t2 <= t1:
if r2 > r1 or c2 < c1 or t2 < t1:
dominated = True
break
if not dominated:
frontier.append(s1)
return frontier
12.4.2 Cost Model
Each action type has a normalized cost weight:
| Action Type | Cost Weight | Rationale |
|---|---|---|
| Credential rotation | 0.5 | Low risk, fully automated |
| Config change | 0.8 | Moderate risk, may require restart |
| Certificate rotation | 1.0 | Requires PKI integration |
| Segmentation | 1.5 | Affects multiple devices |
| Firmware update | 2.0 | High risk, potential brick |
Evidence label: Illustrative. Method note: these cost weights are normalized policy priors that let the planner compare unlike tasks on one scale. Assumptions: the teaching planner needs a compact cross-action cost model. Boundary: recalibrate the weights for the target environment’s staffing model and maintenance rules. The Pareto frontier lets operators choose between strategies that focus on reducing risk the most, keeping costs low, or finding a balance between the two. We need these objectives.
12.5.1 The Default Credential Problem
Phase 7 (Default Credentials) identifies devices with factory passwords. Phase 12 rotates these credentials through a five-step process:
Detect -> Generate -> Rotate -> Verify -> Store
12.5.2 Password Generation
The CredentialRotator generates cryptographically secure passwords meeting per-protocol minimum length requirements:
# From apps/api/app/scanning/remediation/credential_rotator.py
_MIN_PASSWORD_LENGTH: dict[str, int] = {
"ssh": 24,
"http": 24,
"telnet": 16,
"rtsp": 20,
"onvif": 20,
}
Passwords are generated using secrets.token_urlsafe() and validated against complexity requirements (uppercase, lowercase, digits, special characters).
12.5.3 Vault Integration
New credentials are stored in HashiCorp Vault via the VaultAdapter:
PUT /v1/secret/data/breakwater/{device_ip}/{protocol}
{
"data": {
"username": "admin",
"password": "<generated>",
"rotated_at": "2026-03-05T14:30:00Z",
"previous_hash": "sha256:abc123..."
}
}
Only the hash of the old password is kept, not the password itself, enabling rollback verification. If something goes wrong during rotation, the system can quickly test and restore the previous credential.
12.6 Firmware Update Orchestration
12.6.1 Firmware Risk
Firmware updates are the riskiest part of remediation. A single mistake can make a device unusable, leave it stuck halfway through an update, or create a security hole across the fleet.
12.6.2 Orchestration Stages
The FirmwareOrchestrator executes firmware updates through six stages:
-
Pre-flight check – verify that the device is reachable, has sufficient storage, and that the update image is signed.
-
Backup current firmware – download and hash the running firmware for rollback.
-
Stage update: upload the new firmware to the device's staging partition.
-
Verify staged image – check hash/signature of the staged firmware.
-
Apply update – trigger the device to install the staged firmware.
-
Post-update verification – confirm that the device starts up correctly and is running the new version.
Each stage has a set timeout. If any step fails, the orchestrator stops the process and requests human intervention.
12.7 Micro-Segmentation Policy Generation
The SegmentationEngine classifies devices into four network zones based on device type, vendor, and service signatures:
# From apps/api/app/scanning/remediation/segmentation_engine.py
ZONE_DEFINITIONS = {
"iot": {
"description": "IoT devices -- cameras, sensors, smart home",
"risk_weight": 1.5,
"allowed_outbound": ["dmz"],
"default_deny_inbound": True,
},
"ot": {
"description": "Operational Technology -- PLCs, SCADA, HMI",
"risk_weight": 2.0,
"allowed_outbound": [],
"default_deny_inbound": True,
},
"it": {
"description": "IT infrastructure -- workstations, servers",
"risk_weight": 1.0,
"allowed_outbound": ["dmz", "iot"],
},
"dmz": {
"description": "Demilitarised zone -- external-facing services",
"risk_weight": 1.2,
"allowed_outbound": ["it"],
},
}
Device classification uses three heuristics in priority order:
-
Device type mapping – 30 device types mapped to zones (e.g., plc -> ot, camera -> iot, server -> it).
-
Vendor heuristics – known IoT vendors (Nest, Ring, Wyze, Tuya) map to IoT; known OT vendors (Siemens, Allen-Bradley, Schneider) map to ot.
-
Port heuristics – IoT-characteristic ports (554, 1883, 5683, 8883) map to IoT; OT-characteristic ports (502, 44818, 20000, 47808) map to ot.
12.7.2 Flow Policy Generation
For each zone, the engine generates least-privilege flow rules based on default allowed flows:
DEFAULT_ALLOWED_FLOWS = [
{"src_zone": "iot", "dst_zone": "dmz", "ports": [443, 8883],
"description": "IoT cloud connectivity (HTTPS, MQTT-TLS)"},
{"src_zone": "it", "dst_zone": "iot", "ports": [80, 443],
"description": "IT management access to IoT devices"},
{"src_zone": "it", "dst_zone": "ot", "ports": [443, 502],
"description": "IT to OT monitoring (restricted)"},
]
Any network flow not included in the approved list is blocked. The engine looks for suspicious flows that break the rules and quickly flags any unauthorized traffic between zones.PolicyExporter translates abstract segmentation policies into vendor-specific configurations:
| Format | Target | Example Output |
|---|---|---|
| iptables | Linux firewalls | iptables -A FORWARD -s 192.168.1.0/24 -d 10.0.0.0/24 -p tcp --dport 443 -j ACCEPT |
| pf | BSD/macOS | pass in on egress proto tcp from 192.168.1.0/24 to 10.0.0.0/24 port 443 |
| Cisco ACL | Cisco IOS | access-list 101 permit tcp 192.168.1.0 0.0.0.255 10.0.0.0 0.0.0.255 eq 443 |
| Palo Alto XML | PAN-OS | <entry name="allow-iot-cloud"><from><member>iot</member></from>... |
| AWS SG | AWS Security Groups | {"IpProtocol": "tcp", "FromPort": 443, "ToPort": 443, "IpRanges": [...]} |
| Azure NSG | Azure Network Security Groups | {"name": "allow-iot-dmz", "direction": "Outbound", ...} |
12.8 The Safety Pipeline
12.8.1 Stage 1: Risk Classification
The SafetyPipeline classifies each plan into risk levels that determine the approval mode:
# From apps/api/app/scanning/remediation/safety_pipeline.py
def classify_risk_level(self, plan):
high_risk_actions = {"firmware_update", "credential_rotation"}
has_high_risk = any(s.action_type.value in high_risk_actions for s in plan.steps)
total_steps = len(plan.steps)
unique_ips = len({s.target_ip for s in plan.steps})
if has_high_risk and total_steps > 10:
return "high"
elif has_high_risk or total_steps > 5 or unique_ips > 10:
return "medium"
else:
return "low"
12.8.2 Stage 2: Digital Twin Simulation
Before any production changes, the plan is simulated in the digital twin from Chapter 6. The TwinPreflight module:
-
Deploys a software-defined network twin from scan topology.
-
Applies each remediation action in the twin.
-
Checks for cascading failures (device becomes unreachable, service stops responding).
-
Verifies compliance postconditions.
If cascading failures are detected, the plan is blocked with status blocked_by_simulation, and no production changes occur.
12.8.3 Stage 3: Postcondition Verification
Three postconditions are verified after the twin simulation:
-
No cascading failures – zero simulated cascading failures.
-
Service continuity – all critical services remain available.
-
Risk reduction – the post-remediation risk score is lower than the pre-remediation score.
async def verify_postconditions(self, plan, sim_result):
checks = []
checks.append({
"check": "no_cascading_failures",
"passed": len(sim_result.get("cascading_failures", [])) == 0,
})
checks.append({
"check": "service_continuity",
"passed": sim_result.get("service_continuity", True),
})
checks.append({
"check": "risk_reduction",
"passed": risk_delta.get("after") <= risk_delta.get("before"),
})
return {"all_passed": all(c["passed"] for c in checks), "checks": checks}
12.8.4 Stage 4: Approval Gate
The approval mode depends on risk level and configuration:
| Risk Level | Default Mode | Behaviour |
|---|---|---|
| Low | Auto | Approved immediately if BREAKWATER_REMEDIATION_APPROVAL_MODE=auto |
| Medium | Timed | Auto-approved if no rejection within the timeout period |
| High | Manual | Requires explicit operator approval via API |
12.8.5 Stage 5: Execution with Checkpoints
Actions are executed in topological order (dependency-aware). Before each action, a rollback checkpoint is created:
async def execute_actions(self, plan):
ordered_steps = self._topo_sort(plan.steps)
for step in ordered_steps:
# Verify dependencies completed
deps_met = all(
any(e["step_id"] == d and e["success"] for e in executed)
for d in step.dependencies
)
if not deps_met:
step.status = StepStatus.failed
continue
# Create rollback checkpoint
checkpoint = rollback_mgr.create_checkpoint(step)
# Execute
step.status = StepStatus.executing
await execute_step(step)
step.status = StepStatus.completed
12.8.6 Stage 6: Health Check
After execution, a health check runs against all affected devices:
-
Reachability – can the device still be pinged?
-
Service availability – are the expected ports still open?
-
Authentication – do the new credentials work?
-
Function verification – is the device performing its intended function?
12.8.7 Stage 7: Conditional Rollback
If a health check fails, the pipeline reverses each completed step in sequence, restoring each device to its pre-action state using the saved checkpoints.
12.9 Approval Gates
12.9.1 Three Approval Modes
The ApprovalGateManager supports three modes configured via BREAKWATER_REMEDIATION_APPROVAL_MODE:
Auto: Low-risk plans are approved immediately. This is appropriate for credential rotations on non-critical devices and configuration changes that have been validated in the twin.
Timed: The plan is approved after a configurable timeout (default 1 hour) unless an operator explicitly rejects it. This provides a window for human review while preventing plans from being indefinitely blocked.
Manual: The plan requires explicit approval via the /v1/remediation/{scan_id}/approve endpoint. This is required for high-risk plans (firmware updates affecting >10 devices, plans touching OT zone devices).
12.9.2 Risk-Based Override
The safety pipeline overrides the configured mode when risk warrants it:
if risk_level == "low" and mode_str == "auto":
mode = ApprovalMode.auto
elif risk_level == "high":
mode = ApprovalMode.manual # Always manual for high risk
The RollbackManager creates a checkpoint before each action. A checkpoint captures:
Step ID – which action this checkpoint belongs to.
Pre-action state – device configuration snapshot (credentials hash, firmware version, firewall rules).
Timestamp – when the checkpoint was created.
Rollback procedure – how to reverse the action (e.g., “re-apply previous credential”, “revert to firmware version X”).
12.10.1 Checkpoint Architecture
The RollbackManager creates a checkpoint before each action. A checkpoint captures:
-
Step ID – which action this checkpoint belongs to.
-
Pre-action state – device configuration snapshot (credentials hash, firmware version, firewall rules).
-
Timestamp – when the checkpoint was created.
-
Rollback procedure – how to reverse the action (e.g., “re-apply previous credential”, “revert to firmware version X”).
12.10.2 Rollback Execution
When health checks fail, rollback proceeds in reverse topological order. Each step’s checkpoint is applied, and a verification check confirms that the pre-action state is restored.
The rollback_plan() method reverses all completed steps:
async def rollback_plan(self, plan):
completed_steps = [s for s in reversed(plan.steps)
if s.status == StepStatus.completed]
for step in completed_steps:
await self.rollback_step(step)
return {"steps_rolled_back": len(completed_steps)}
12.11 Compliance-as-Code
12.11.1 Three Framework Implementations
The ComplianceEngine evaluates scan findings against three industrial security frameworks as a screening and control-alignment exercise:
IEC 62443 (Industrial Automation Security): Evaluates controls across Security Levels SL1-SL4 covering identification, authentication, authorization, data integrity, restricted data flow, timely response, and resource availability.
NIST 800-82 (Guide to ICS Security): Covers access control, audit, security assessment, configuration management, incident response, and system/communications protection.
EU Cyber Resilience Act (Regulation 2024/2847): Evaluates the 13 essential security requirements, including vulnerability handling, secure-by-default, automatic updates, incident reporting, and SBOM requirements.
12.11.2 Assessment Architecture
# From apps/api/app/scanning/remediation/compliance_engine.py
class ComplianceEngine:
def assess(self, framework, hosts, findings):
handler = {
"iec62443": self.assess_iec62443,
"nist80082": self.assess_nist80082,
"eucra": self.assess_eucra,
}.get(framework)
return handler(hosts, findings)
A specific check function or a heuristic fallback evaluates each control. The check function examines scan data for evidence of control alignment (e.g., “all devices require authentication” checks whether any device has default credentials). Results are classified as:
-
Passed – control is fully satisfied.
-
Partial – control is partially satisfied (1-2 issues found).
-
Failed – control is not satisfied (3+ issues found).
12.11.3 Compliance Score
The screening score is computed as:
score = ((passed + partial * 0.5) / total) * 100
12.11.4 Gap-to-Remediation Mapping
The generate_remediation_for_gaps() method creates remediation steps for each failed or partial control:
def generate_remediation_for_gaps(self, report):
for control in the report.controls:
if control.status == ComplianceStatus.passed:
continue
steps.append(RemediationStep(
description=f"[{report.framework}] {control.control_id}: "
f"{control.title} ({control.status.value})",
action_type=action_map.get(control.remediation_action),
))
return steps
12.11.5 Compliance Delta
After remediation, the engine computes the improvement:
def compute_compliance_delta(self, before, after):
return {
"score_before": before.compliance_score,
"score_after": after.compliance_score,
"controls_fixed": after.passed - before.passed,
"remaining_gaps": after.failed + after.partial,
"improvement_pct": ((after.score - before.score) / before.score) * 100,
}
graph TD
A[Scan Data + Findings] --> B[IEC 62443 Assessment]
A --> C[NIST 800-82 Assessment]
A --> D[EU CRA Assessment]
B --> E[Compliance Report]
C --> E
D --> E
E --> F[Gap Analysis]
F --> G[Remediation Steps]
G --> H[Plan Engine]
H --> I[Execute Remediation]
I --> J[Re-assess Compliance]
J --> K[Compliance Delta Report]
style E fill:#e1f5fe
style F fill:#ffcdd2
style K fill:#c8e6c9
12.12 Causal Remediation Graphs
12.12.1 The Causal Structure of Vulnerabilities
Vulnerabilities are not independent. A default credential on a camera (root cause) enables lateral movement to the NAS (intermediate effect), which enables data exfiltration (final consequence). Remediating the root cause can collapse much of that causal chain, even if other contributing paths remain.
The CausalGraph module builds directed acyclic graphs from remediation steps, identifying:
-
Root causes – steps with no incoming dependencies (e.g., credential rotation, firmware update).
-
Intermediate effects – steps that depend on root causes (e.g., attack path breaks that become unnecessary after credential rotation).
-
Redundant steps – steps that would be automatically resolved by executing a higher-priority root cause.
12.12.2 Optimization via Causal Pruning
By identifying causal relationships, the planner can prune redundant steps. If rotating credentials on device X eliminates the attack path through X, the “break attack path at X” step can be removed, reducing plan complexity and execution time.
12.13 Self-Healing Policies
12.13.1 The Configuration Drift Problem
Remediation is not a one-time fix. IoT devices may reboot, get reset to factory settings, or be reconfigured. Segmentation rules can change, and new devices can show up. Without ongoing attention, security can gradually weaken.
The SelfHealingMonitor detects three drift categories:
-
Configuration reset – a device reboots and loses its applied policy (common with IoT devices that store configuration in volatile memory).
-
Topology change – new devices join or leave the network, invalidating zone assignments and flow policies.
-
Policy drift – firewall rules are modified externally (by another administrator, a management tool, or a compromised device).
# From apps/api/app/scanning/remediation/self_healing.py
class SelfHealingMonitor:
async def monitor_drift(self, policies, interval=3600):
drift_events = []
for policy in policies:
for device_ip in policy.devices:
reset = await self.detect_config_reset(device_ip, {
"zone": policy.zone,
"expected_rules": len(policy.allowed_flows) + len(policy.denied_flows),
})
if reset:
drift_events.append({
"type": "config_reset",
"device_ip": device_ip,
"auto_remediate": True,
})
return drift_events
12.13.3 Auto-Remediation Loop
When drift is detected, and auto-remediation is enabled, the monitor automatically reapplies the correct policy. This creates a self-sustaining enforcement loop:
Monitor -> Detect Drift -> Re-generate Policy -> Re-apply -> Verify -> Monitor
The loop runs at a configurable interval (BREAKWATER_REMEDIATION_SELF_HEALING_ENABLED=true, default interval: 3600 seconds). Each cycle produces an audit record for compliance reporting.
12.14 Evidence Packaging
12.14.1 Compliance Evidence
The EvidencePackage module collects all evidence generated during remediation execution into a structured package suitable for compliance audits:
-
Plan metadata – plan ID, scan ID, risk classification, and approval records.
-
Execution timeline – timestamped log of every pipeline stage.
-
Health check results – per-device health check outcomes.
-
Rollback records – any rollback actions with reasons.
-
Compliance delta – before/after compliance scores with per-control evidence.
-
Digital twin simulation – simulation inputs and outcomes.
12.14.2 Audit Trail
Every action in the safety pipeline produces a structured audit entry:
def _log_stage(self, stage, data):
self._execution_log.append({
"stage": stage,
"timestamp": datetime.now(timezone.utc).isoformat(),
"data": data,
})
The complete execution log is included in the remediation result, providing a full audit trail from plan generation through execution and health monitoring.
12.D Seminar War Rooms
This section is intentionally demanding. Each war room asks the reader to work like a senior analyst responsible for remediation planner decisions in live IoT or OT environments. The task is not to recite the chapter. The task is to make a bounded claim under pressure, then defend the evidence boundary when another expert attacks it.
12.D1 Plant-Breaking Patch
War Room 1 begins with the plant-breaking patch. The first analyst wants to accept the change action because it fits the expected story. The second analyst refuses to move until the health contract is tied to an observed artifact, an owner, and a clock. The disagreement is productive. It prevents the team from treating a plausible explanation as a verified.
The class should interrogate the case by changing one fact that a real adversary could influence: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives the change and which claim fails. A doctoral answer does not hide behind caution. It chooses a precise operational state: admit, hold, shadow- test, collect, rollback, or reject.
The final artifact for the plant-breaking patch is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and rollback gate. It also contains one sentence for leadership that is weaker than the analyst wants and stronger than a lawyer would fear. That sentence is the craft. It carries enough truth to guide action without smuggling in facts the system did not prove.
For a plant-breaking patch, change one adversary-controlled fact: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives and which claim fails. A doctoral answer chooses a precise operational state rather than hiding behind generic caution.
The final artifact for the plant-breaking patch is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and recovery or hold gate. It also contains one leadership sentence that guides action without smuggling in facts that the system did not prove.
12.D2 Airport Firewall Dependency
War Room 2 begins with the airport firewall dependency. The first analyst wants to accept the change action because it fits the expected story. The second analyst refuses to move until the health contract is tied to an observed artifact, an owner, and a clock. The disagreement is productive. It prevents the team from treating a plausible explanation as a verified one.
The class should challenge the case by changing one fact that a real adversary could influence: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives the change and which claim fails. A doctoral answer does not hide behind caution. It chooses a precise operational state: admit, hold, shadow- test, collect, rollback, or reject.
The final artifact for the airport firewall dependency is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and rollback gate. It also contains one sentence for leadership that is weaker than the analyst wants and stronger than a lawyer would fear. That sentence is the craft. It carries enough truth to guide action without smuggling in facts the system did not prove.
For airport firewall dependency, change one adversary-controlled fact: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives and which claim fails. A doctoral answer chooses a precise operational state rather than hiding behind generic caution.
The final artifact for the airport firewall dependency is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and recovery or hold gate. It also contains one leadership sentence that guides action without smuggling in facts that the system did not prove.
12.D3 Evidence Access Rotation
War Room 3 begins with the evidence access rotation. The first analyst wants to accept the change action because it fits the expected story. The second analyst refuses to move until the health contract is tied to an observed artifact, an owner, and a clock. The disagreement is productive. It prevents the team from treating a plausible explanation as verified.
The class should bound the case by changing one fact that a real adversary could influence: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives the change and which claim fails. A doctoral answer does not hide behind caution. It chooses a precise operational state: admit, hold, shadow-test, collect, rollback, or reject.
The final artifact for the evidence access rotation is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and rollback gate. It also contains one leadership sentence that is weaker than the analyst wants and stronger than a lawyer would fear. That sentence is the craft. It carries enough truth to guide action without smuggling in facts the system did not prove.
For evidence access rotation, change one adversary-controlled fact: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives and which claim fails. A doctoral answer chooses a precise operational state rather than hiding behind generic caution.
The final artifact for evidence access rotation is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and recovery or hold gate. It also contains one leadership sentence that guides action without smuggling in facts that the system did not prove.
12.D4 Maintenance-Window Firmware
War Room 4 begins with the maintenance window firmware. The first analyst wants to accept the change action because it fits the expected story. The second analyst refuses to move until the health contract is tied to an observed artifact, an owner, and a clock. The disagreement is productive. It prevents the team from treating a plausible explanation as verified.
The class should quarantine the case by changing one fact that a real adversary could influence: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives the change and which claim fails. A doctoral answer does not hide behind caution. It chooses a precise operational state: admit, hold, shadow- test, collect, rollback, or reject.
The final artifact for the maintenance-window firmware is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and rollback gate. It also contains one leadership sentence that is weaker than the analyst wants and stronger than a lawyer would fear. That sentence is the craft. It carries enough truth to guide action without smuggling in facts the system did not prove.
For maintenance-window firmware, change one adversary-controlled fact: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives and which claim fails. A doctoral answer chooses a precise operational state rather than hiding behind generic caution.
The final artifact for maintenance-window firmware is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and recovery or hold gate. It also contains one leadership sentence that guides action without smuggling in facts that the system did not prove.
12.D5 Residential Rollback
War Room 5 begins with the residential rollback. The first analyst wants to accept the change action because it fits the expected story. The second analyst refuses to move until the health contract is tied to an observed artifact, an owner, and a clock. The disagreement is productive. It prevents the team from treating a plausible explanation as a verified one.
The class should simulate the case by changing one fact that a real adversary could influence: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives the change and which claim fails. A doctoral answer does not hide behind caution. It chooses a precise operational state: admit, hold, shadow- test, collect, rollback, or reject.
The final artifact for the residential rollback is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and rollback gate. It also contains one sentence for leadership that is weaker than the analyst wants and stronger than a lawyer would fear. That sentence is the craft. It carries enough truth to guide action without smuggling in facts the system did not prove.
For residential rollback, change one adversary-controlled fact: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives and which claim fails. A doctoral answer chooses a precise operational state rather than hiding behind generic caution.
The final artifact for residential rollback is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and recovery or hold gate. It also contains one leadership sentence that guides action without smuggling in facts that the system did not prove.
12.D6 Hospital Segmentation
War Room 6 begins with the hospital segmentation. The first analyst wants to accept the change action because it fits the expected story. The second analyst refuses to move until the health contract is tied to an observed artifact, an owner, and a clock. The disagreement is productive. It prevents the team from treating a plausible explanation as a verified one.
The class should replay the case by changing one fact that a real adversary could influence: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives the change and which claim fails. A doctoral answer does not hide behind caution. It chooses a precise operational state: admit, hold, shadow-test, collect, rollback, or reject.
The final artifact for the hospital segmentation is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and rollback gate. It also contains one leadership sentence that is weaker than the analyst wants and stronger than a lawyer would fear. That sentence is the craft. It carries enough truth to guide action without smuggling in facts the system did not prove.
For hospital segmentation, change one adversary-controlled fact: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives and which claim fails. A doctoral answer chooses a precise operational state rather than hiding behind generic caution.
The final artifact for hospital segmentation is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and recovery or hold gate. It also contains one leadership sentence that guides action without smuggling in facts that the system did not prove.
12.D7 Approval Expiry
War Room 7 begins with the approval expiry. The first analyst wants to accept the change action because it fits the expected story. The second analyst refuses to move until the health contract is tied to an observed artifact, an owner, and a clock. The disagreement is productive. It prevents the team from treating a plausible explanation as verified.
The class should audit the case by changing one fact that a real adversary could influence: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives the change and which claim fails. A doctoral answer does not hide behind caution. It chooses a precise operational state: admit, hold, shadow-test, collect, rollback, or reject.
The final artifact for the approval expiry is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and rollback gate. It also contains one leadership sentence that is weaker than the analyst wants and stronger than a lawyer would fear. That sentence is the craft. It carries enough truth to guide action without smuggling in facts the system did not prove.
For approval expiry, change one adversary-controlled fact: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives and which claim fails. A doctoral answer chooses a precise operational state rather than hiding behind generic caution.
The final artifact for approval expiry is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and recovery or hold gate. It also contains one leadership sentence that guides action without smuggling in facts that the system did not prove.
12.D8 Self-Healing Drift
War Room 8 begins with the self-healing drift. The first analyst wants to accept the change action because it fits the expected story. The second analyst refuses to move until the health contract is tied to an observed artifact, an owner, and a clock. The disagreement is productive. It prevents the team from treating a plausible explanation as verified.
The class should stage the case by changing one fact that a real adversary could influence: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives the change and which claim fails. A doctoral answer does not hide behind caution. It chooses a precise operational state: admit, hold, shadow-test, collect, rollback, or reject.
The final artifact for the self-healing drift is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and rollback gate. It also contains one leadership sentence that is weaker than the analyst wants and stronger than a lawyer would fear. That sentence is the craft. It carries enough truth to guide action without smuggling in facts the system did not prove.
The final artifact for self-healing drift is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and recovery or hold gate. It also contains one leadership sentence that guides action without smuggling in facts that the system did not prove.
The final artifact for self-healing drift is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and recovery or hold gate. It also contains one leadership sentence that guides action without smuggling in facts that the system did not prove.
12.D9 Compliance Runtime Risk
War Room 9 begins with the compliance runtime risk. The first analyst wants to accept the change action because it fits the expected story. The second analyst refuses to move until the health contract is tied to an observed artifact, an owner, and a clock. The disagreement is productive. It prevents the team from treating a plausible explanation as verified.
The class should defer the case by changing one fact that a real adversary could influence: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives the change and which claim fails. A doctoral answer does not hide behind caution. It chooses a precise operational state: admit, hold, shadow-test, collect, rollback, or reject.
The final artifact for the compliance runtime risk is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and rollback gate. It also contains one leadership sentence that is weaker than the analyst wants and stronger than a lawyer would fear. That sentence is the craft. It carries enough truth to guide action without smuggling in facts the system did not prove.
For compliance runtime risk, change one adversary-controlled fact: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives and which claim fails. A doctoral answer chooses a precise operational state rather than hiding behind generic caution.
The final artifact for compliance runtime risk is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and recovery or hold gate. It also contains one leadership sentence that guides action without smuggling in facts that the system did not prove.
12.D10 Autonomy Dispute
War Room 10 begins with the autonomy dispute. The first analyst wants to accept the change action because it fits the expected story. The second analyst refuses to move until the health contract is tied to an observed artifact, an owner, and a clock. The disagreement is productive. It prevents the team from treating a plausible explanation as verified.
The class should escalate the case by changing one fact that a real adversary could influence: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives the change and which claim fails. A doctoral answer does not hide behind caution. It chooses a precise operational state: admit, hold, shadow- test, collect, rollback, or reject.
The final artifact for the autonomy dispute is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and rollback gate. It also contains one leadership sentence that is weaker than the analyst wants and stronger than a lawyer would fear. That sentence is the craft. It carries enough truth to guide action without smuggling in facts the system did not prove.
For an autonomy dispute, change one adversary-controlled fact: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives and which claim fails. A doctoral answer chooses a precise operational state rather than hiding behind generic caution.
The final artifact for the autonomy dispute is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and recovery or hold gate. It also contains one leadership sentence that guides action without smuggling in facts that the system did not prove.
12.D11 Weak Health Check
War Room 11 begins with a weak health check. The first analyst wants to accept the change action because it fits the expected story. The second analyst refuses to move until the health contract is tied to an observed artifact, an owner, and a clock. The disagreement is productive. It prevents the team from treating a plausible explanation as verified.
The class should rollback the case by changing one fact that a real adversary could influence: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives the change and which claim fails. A doctoral answer does not hide behind caution. It chooses a precise operational state: admit, hold, shadow- test, collect, rollback, or reject.
The final artifact for the weak health check is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and rollback gate. It also contains one leadership sentence that is weaker than the analyst wants and stronger than a lawyer would fear. That sentence is the craft. It carries enough truth to guide action without smuggling in facts the system did not prove.
For a weak health check, change one adversary-controlled fact: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives and which claim fails. A doctoral answer chooses a precise operational state rather than hiding behind generic caution.
The final artifact for a weak health check is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and recovery or hold gate. It also contains one leadership sentence that guides action without smuggling in facts that the system did not prove.
12.D12 Dependency Graph Surprise
War Room 12 begins with the surprise dependency graph. The first analyst wants to accept the change action because it fits the expected story. The second analyst refuses to move until the health contract is tied to an observed artifact, an owner, and a clock. The disagreement is productive. It prevents the team from treating a plausible explanation as verified.
The class should instrument the case by changing one fact that a real adversary could influence: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives the change and which claim fails. A doctoral answer does not hide behind caution. It chooses a precise operational state: admit, hold, shadow- test, collect, rollback, or reject.
The final artifact for the dependency graph surprise is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and rollback gate. It also contains one leadership sentence that is weaker than the analyst wants and stronger than a lawyer would fear. That sentence is the craft. It carries enough truth to guide action without smuggling in facts the system did not prove.
For the dependency graph surprise, change one adversary-controlled fact: timing, identity, provenance, replay, exception handling, sampling, maintenance state, or operator pressure. The answer must state which claim survives and which claim fails. A doctoral answer chooses a precise operational state rather than hiding behind generic caution.
The final artifact for the dependency graph surprise is a compact evidence packet. It contains the input record, transformation, unresolved conflict, decision authority, and recovery or hold gate. It also contains one leadership sentence that guides action without smuggling in facts that the system did not prove.
12.E Adversarial Oral Examination
These oral-exam prompts are designed to make expert students uncomfortable in the right way. Each prompt forces a precise claim about remediation authority, then changes one operational fact that could occur in a real IoT or OT environment.
12.E1 When Rollback command exists but was never tested
The examiner gives the student a clean initial narrative, then reveals that rollback command exists but was never tested. The student must decide whether the original recommendation survives. A passing answer does not retreat into general caution. It names the exact sentence that must be weakened and the exact evidence that would restore it.
The expected response has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary, they have not mastered the chapter.
The expected response has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be brief enough to use during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary, they have not mastered the chapter.
The examiner gives the student a clean initial narrative, then reveals that health check misses business workflow. The student must decide whether the original recommendation survives. A passing answer does not retreat into general caution. It names the exact sentence that must be weakened and the exact evidence that would restore it.
The expected response has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary, they have not mastered the chapter.
The expected response for health check misses business workflow has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary for this prompt, the student has not mastered the chapter.
12.E3 When Approval belongs to an expired window
The examiner gives the student a clean initial narrative, then reveals that the approval falls within an expired window. The student must decide whether the original recommendation survives. A passing answer does not retreat into general caution. It names the exact sentence that must be weakened and the exact evidence that would restore it.
The expected response has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary, they have not mastered the chapter.
The expected response for approval within the expired window includes four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and the next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary for this prompt, the student has not mastered the chapter.
12.E4 When Simulation ignores vendor vpn path
The examiner gives the student a clean initial narrative, then reveals that the simulation ignores the vendor VPN path. The student must decide whether the original recommendation survives. A passing answer does not retreat into general caution. It names the exact sentence that must be weakened and the exact evidence that would restore it.
The expected response has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary, they have not mastered the chapter.
The expected response for simulation ignores the vendor vpn path, which has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary for this prompt, the student has not mastered the chapter.
12.E5 When Patch fixes the scanner and breaks safety
The examiner gives the student a clean initial narrative, then reveals that the patch fixes the scanner and breaks safety. The student must decide whether the original recommendation survives. A passing answer does not retreat into general caution. It names the exact sentence that must be weakened and the exact evidence that would restore it.
The expected response has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary, they have not mastered the chapter.
The expected response for patch fixes scanner and breaks safety has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary for this prompt, the student has not mastered the chapter.
12.E6 When Segmentation cuts off evidence collection
The examiner gives the student a clean initial narrative, then reveals that segmentation cuts off evidence collection. The student must decide whether the original recommendation survives. A passing answer does not retreat into general caution. It names the exact sentence that must be weakened and the exact evidence that would restore it.
The expected response has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary, they have not mastered the chapter.
The expected response for segmentation cuts off evidence collection has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary for this prompt, the student has not mastered the chapter.
12.E7 When Self-healing repeats a bad change
The examiner gives the student a clean initial narrative, then reveals that self-healing repeats a bad change. The student must decide whether the original recommendation survives. A passing answer does not retreat into general caution. It names the exact sentence that must be weakened and the exact evidence that would restore it.
The expected response has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary, they have not mastered the chapter.
The expected response for self-healing repeats a bad change has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary for this prompt, the student has not mastered the chapter.
12.E8 When Compliance fix creates runtime drift
The examiner gives the student a clean initial narrative, then reveals that the compliance fix creates runtime drift. The student must decide whether the original recommendation survives. A passing answer does not retreat into general caution. It names the exact sentence that must be weakened and the exact evidence that would restore it.
The expected response has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be short enough to brief during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary, they have not mastered the chapter.
The expected response for compliance fix creates runtime drift has four parts: current operational state, evidence still admissible, evidence now contaminated or incomplete, and next collection step. The answer should be brief enough to use during an incident and rigorous enough for another senior analyst to reproduce. If the student cannot name the boundary for this prompt, they have not mastered the chapter.
Phase 12 also has four trust boundaries that should remain explicit.
First, the planner’s risk-reduction and cost values are policy priors useful for ranking actions. They are not direct measurements of expected reductions in loss or labor consumption. Implementation is computed over a bounded candidate set. It represents the frontier of the explored search space, not proof that no better plan exists outside that set.
Third, digital twin preflight is a structural safety screen. It catches dependency breaks, service loss, and some cascade conditions. It does not fully model plant physics, undocumented human workarounds, or every vendor-specific state transition.
Fourth, the audit package strengthens accountability and later review. It does not guarantee regulatory sufficiency, legal admissibility, or operational correctness by itself. These still depend on change-control practice, evidence handling, and domain review.
12. B Deep Technical Expansion
12.B1 Execution authority matrix
Autonomous remediation needs an authority matrix. Recommendation, staging, simulation, low-risk execution, and high-risk execution are different powers, each requiring a different evidence threshold.
The matrix should name both the action and the asset class. Restarting a lab camera is not the same authority as changing a firewall rule for a police evidence network. Rotating a test credential is not the same as patching a PLC during production. The verb alone is not enough; the object determines the risk.
Each cell in the matrix should have a required proof bundle: triggering evidence, simulation result, blast-radius estimate, health check, rollback command, approval record, and post-action observation window. Autonomy without this bundle is speed without accountability.
12.B2 Health checks as contracts
A health check should be a contract, not a ping. It must test the service, dependency, policy, and business function the action could break. Weak health checks create false rollback confidence.
The health check must match the action. A firewall change tests allowed flows, denied flows, logging, and exception paths. A firmware rollback tests device role, protocol behavior, local control safety, and management-plane recovery. A credential rotation tests every dependent service, not just the account that changed.
For expert operators, the key question is whether the health check would catch the failure that matters. A web status code will not catch a broken badge-reader workflow. A single ICMP response will not catch a safety interlock failure. The system must fail closed when the check is too weak for the proposed action.
12. A Advanced Practitioner Fieldbook: What Experts Still Miss
This fieldbook expands Chapter 12 for doctoral students and senior cybersecurity practitioners. It assumes the reader knows the vocabulary. The goal is harder. The reader must reason under pressure, preserve evidence boundaries, and explain why the analytic is trustworthy when the environment fights back.
The prose uses short sentences on purpose. Short sentences expose weak claims and make the material teachable in a live seminar.
12.A1 The Patch That Fixed the Scanner and Broke the Plant
For the patch that fixed the scanner and broke the plant, the review starts with the change action and ends only when the claim has a named owner. The analyst must state what the system observed, what transformation changed the record, and what conclusion is still forbidden. It shows that remediation is not finished when the scanner turns green.
For the patch that fixed the scanner and broke the plant, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
The specific danger in the patch that fixed the scanner and broke the plant is false closure. The health contract may support one interpretation while the authority record points to another. The case must remain open until the rollback gate explains why the stronger claim is admissible or why it has been refused.
A senior answer for the patch that fixed the scanner and broke the plant produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts must agree on the same boundary. If they do not, the analyst has confused persuasion with proof.
The planner is a controller. The network is the plant. Findings are observations. Actions change state.
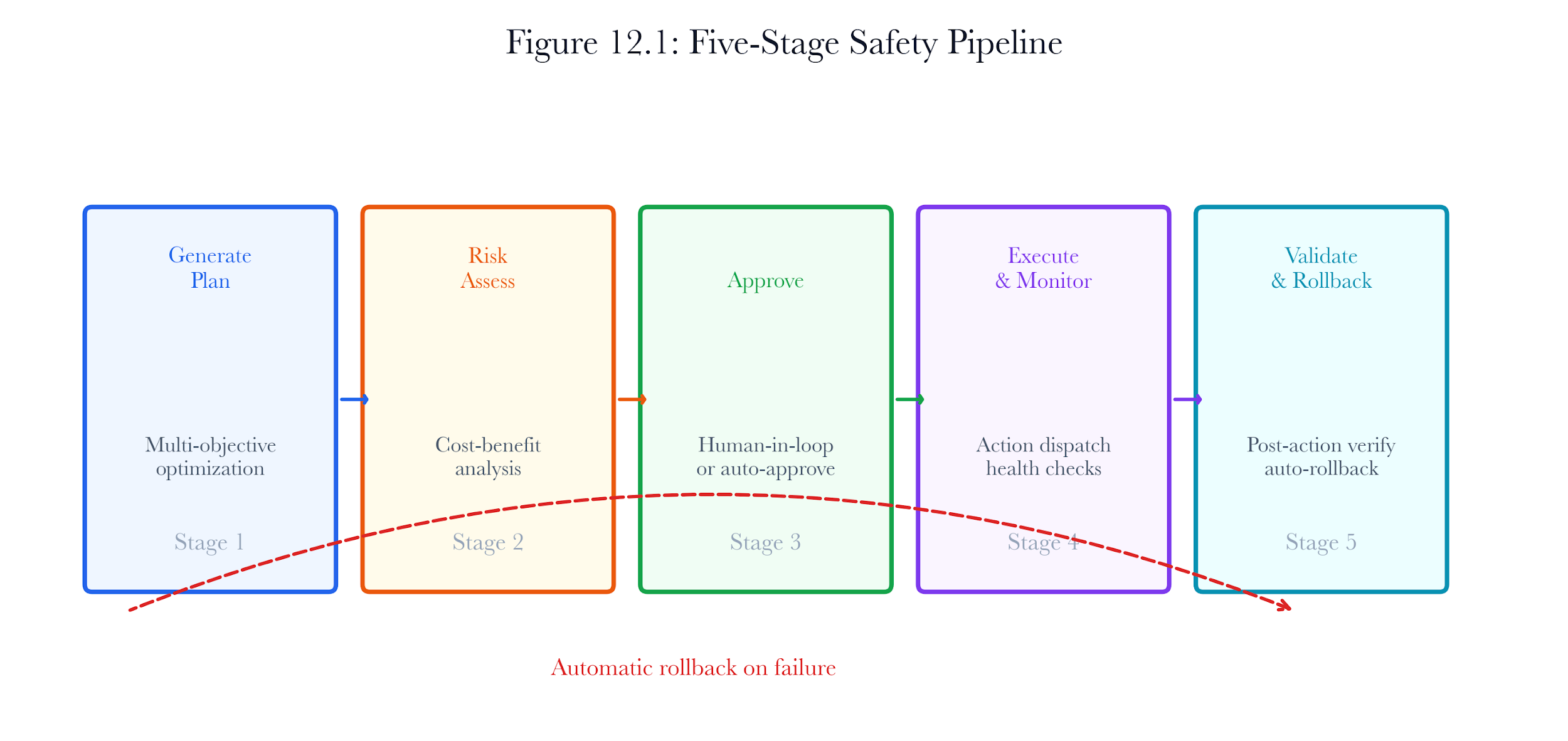
Figure 12.A2: ch12 fig01 five stage safety pipeline.
Figure note: The seven-stage pipeline belongs with control theory. It separates classification, simulation, verification, authority, execution, observation, and rollback.
For remediation as control theory, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
The specific danger in remediation as control theory, is false closure. A health contract may support one interpretation while an authority record points toward another. The case should remain open until the rollback gate explains why the stronger claim is admissible or why it has been refused.
A senior answer for Pareto frontiers for grownups produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts must agree on the same boundary. If they do not, the analyst has confused persuasion with proof.
Risk, cost, and downtime do not collapse into one truth. The frontier shows governance choices.
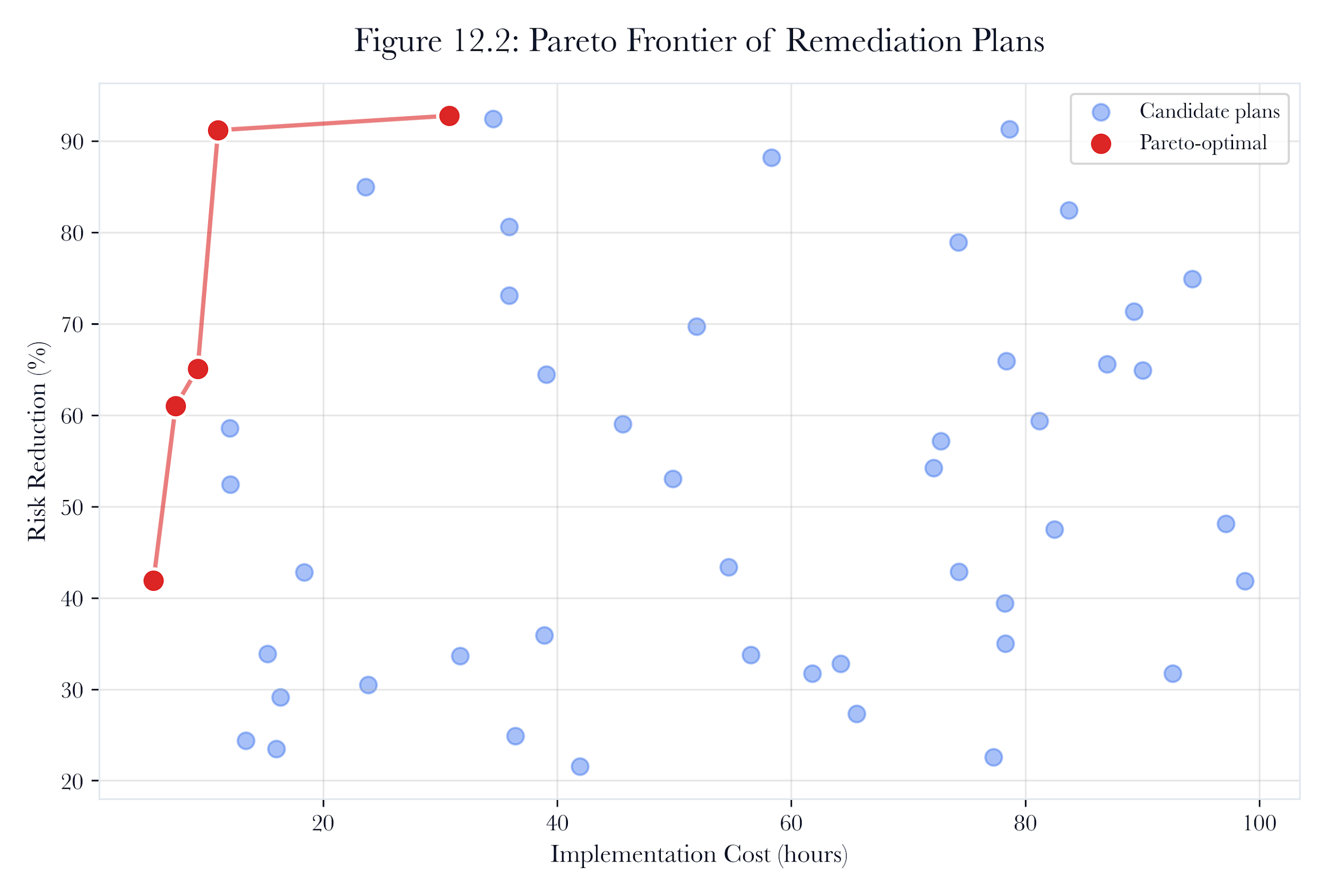
Figure 12.A3: ch12 fig02 pareto frontier.
Figure note: The Pareto frontier corresponds to mature trade-offs. It prevents a single risk score from hiding downtime, safety, and labor cost.
For Pareto frontiers for grownups, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
The specific danger in Pareto frontiers for grownups is false closure. A health contract may support one interpretation while an authority record points toward another. The case should remain open until the rollback gate explains why the stronger claim is admissible or why it has been refused.
A senior answer for Pareto frontiers for grownups produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts should agree on the same boundary. If they do not, the analyst has confused persuasion with proof.
12.A4 Credential rotation without self-lockout
Rotation requires old credential failure, new credential success, Vault write success, and dependency verification.
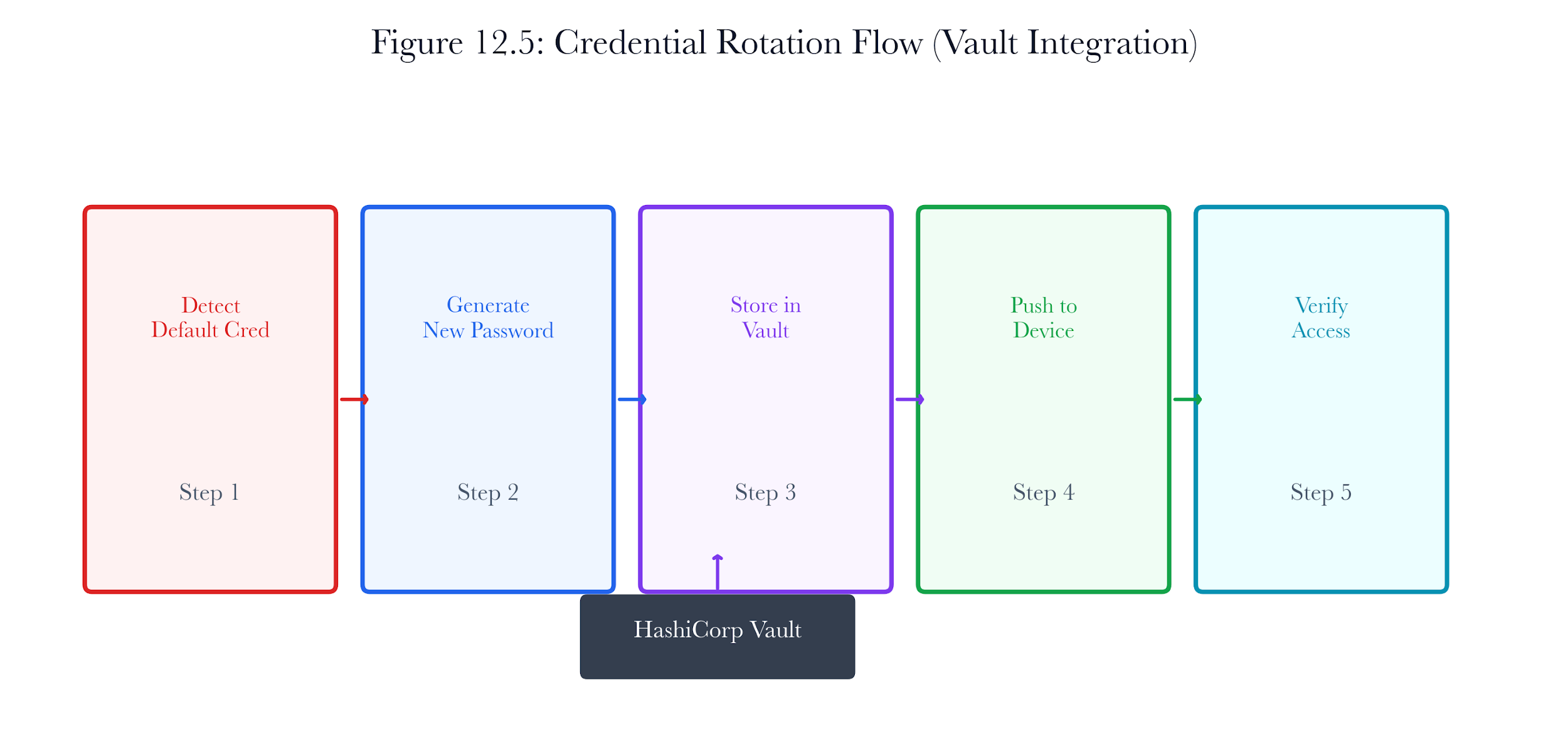
Figure 12.A4: ch12 fig05 credential rotation flow.
Figure note: Credential rotation needs a flow, not a checkbox. The figure shows where self-lockout and dependency breakage enter.
For credential rotation without self-lockout, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
A senior answer for credential rotation without self-lockout produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts must agree on the same boundary. If they do not, the analyst has confused persuasion with proof.
A senior answer for credential rotation without self-lockout produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts should agree on the same boundary. If they do not, the analyst has confused persuasion with proof.
12.A5 Firmware orchestration under maintenance windows
Firmware work is calendar work. Dependencies, reboot distributions, staffing, and rollback packages decide safety.
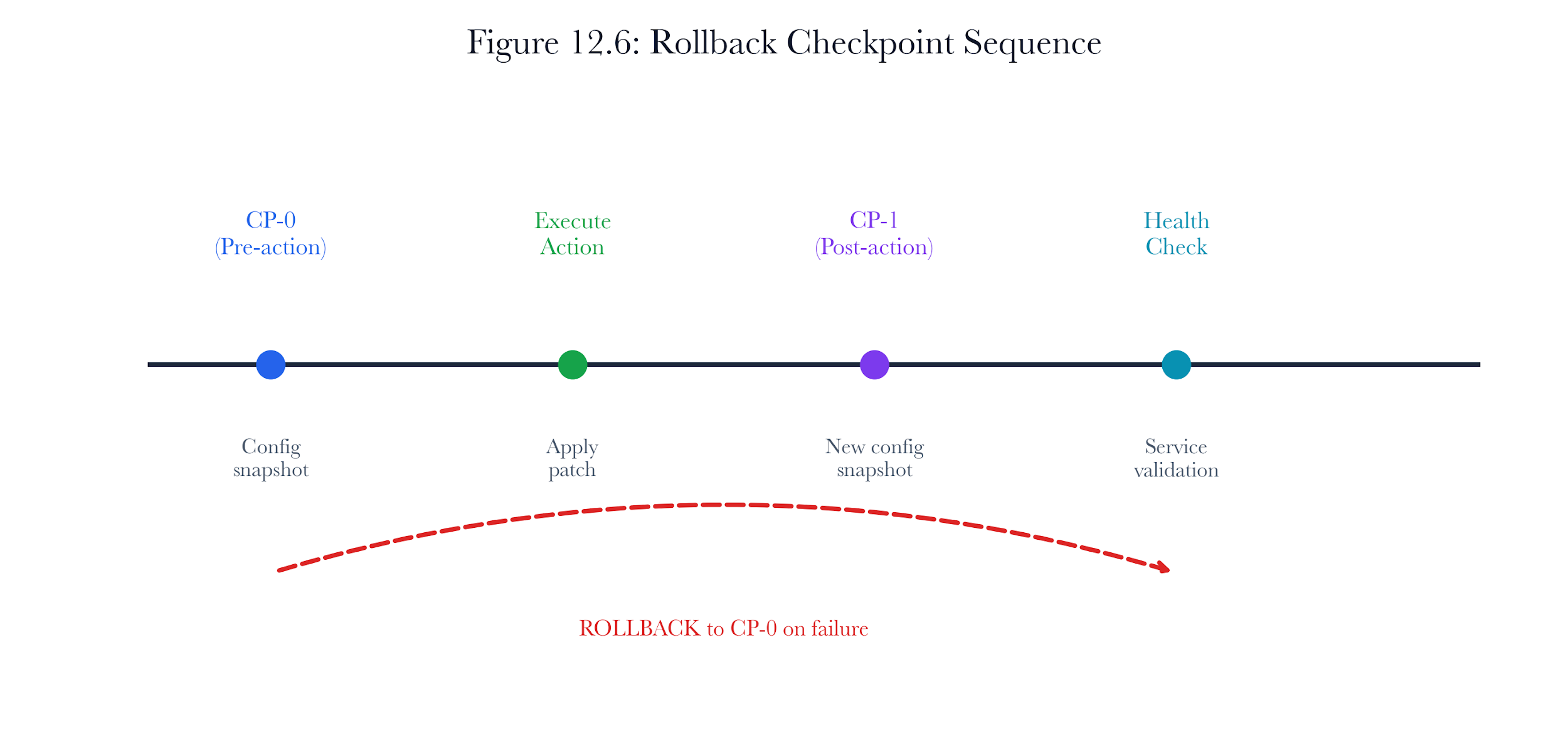
Figure 12.A5: ch12 fig06 rollback checkpoint sequence.
Figure note: Rollback checkpoints belong with firmware orchestration. They make reversibility visible before a maintenance window closes.
For firmware orchestration under maintenance windows, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
The specific danger in firmware orchestration under maintenance windows is false closure. The health contract may support one interpretation while the authority record points to another. The case must remain open until the rollback gate explains why the stronger claim is admissible or why it has been refused.
A senior answer for firmware orchestration under maintenance windows produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts must agree on the same boundary. If they do not, the analyst has confused persuasion with proof.
A diagram does not block a packet. Exported vendor policy does.
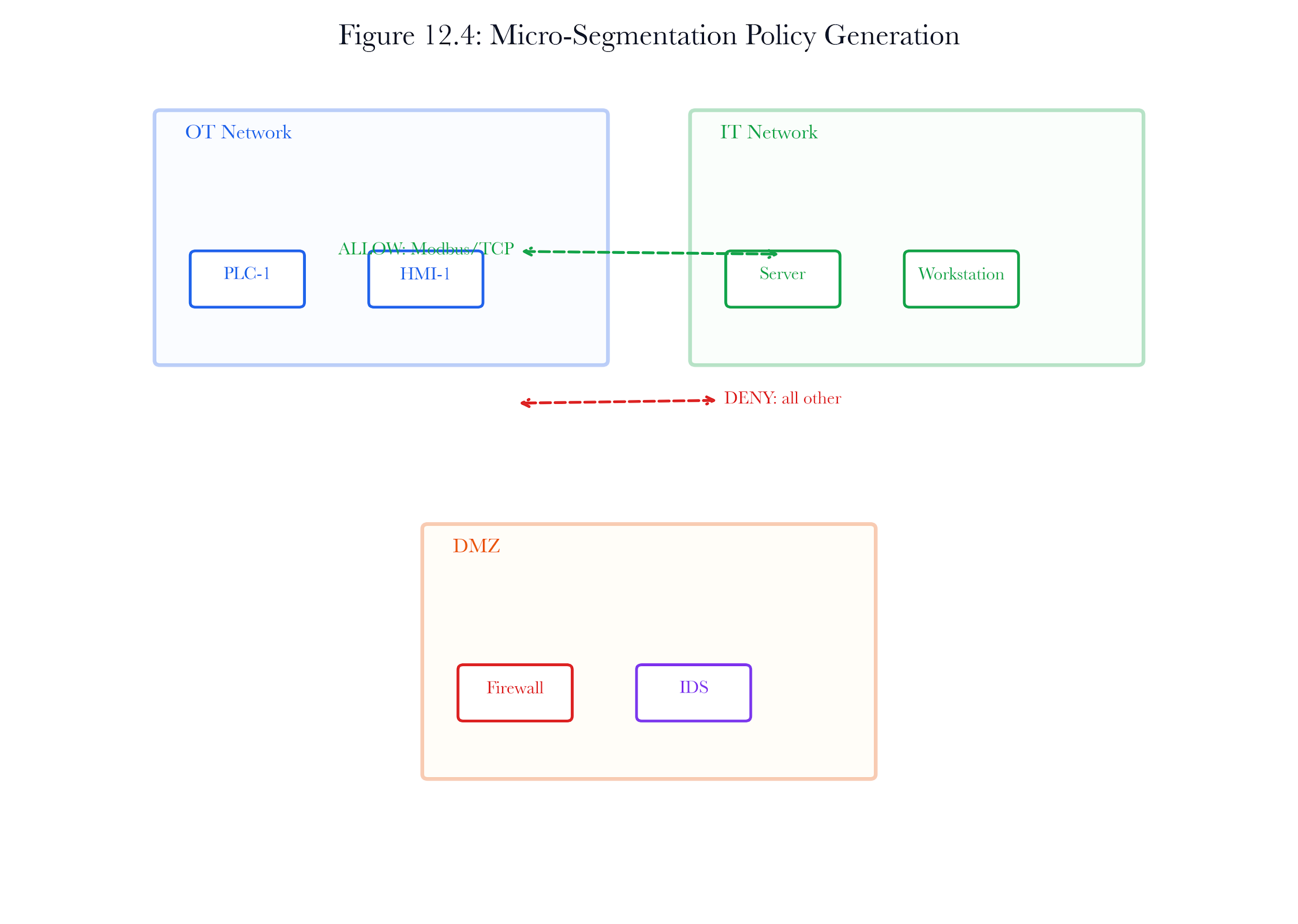
Figure 12.A6: ch12 fig04 micro segmentation policy.
Figure note: Micro-segmentation policy belongs with executable controls. The figure shows how an abstract intent gives rise to allowed and denied flows.
For micro-segmentation as an executable policy, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
A senior answer for micro-segmentation as an executable policy produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts must agree on the same boundary. If they do not, the analyst has confused persuasion with proof.
A senior answer for micro-segmentation as an executable policy produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts should agree on the same boundary. If they do not, the analytic has confused persuasion with proof.
12.A7 Approval as safety logic
Approval encodes consequence, uncertainty, and authority. It is control logic.
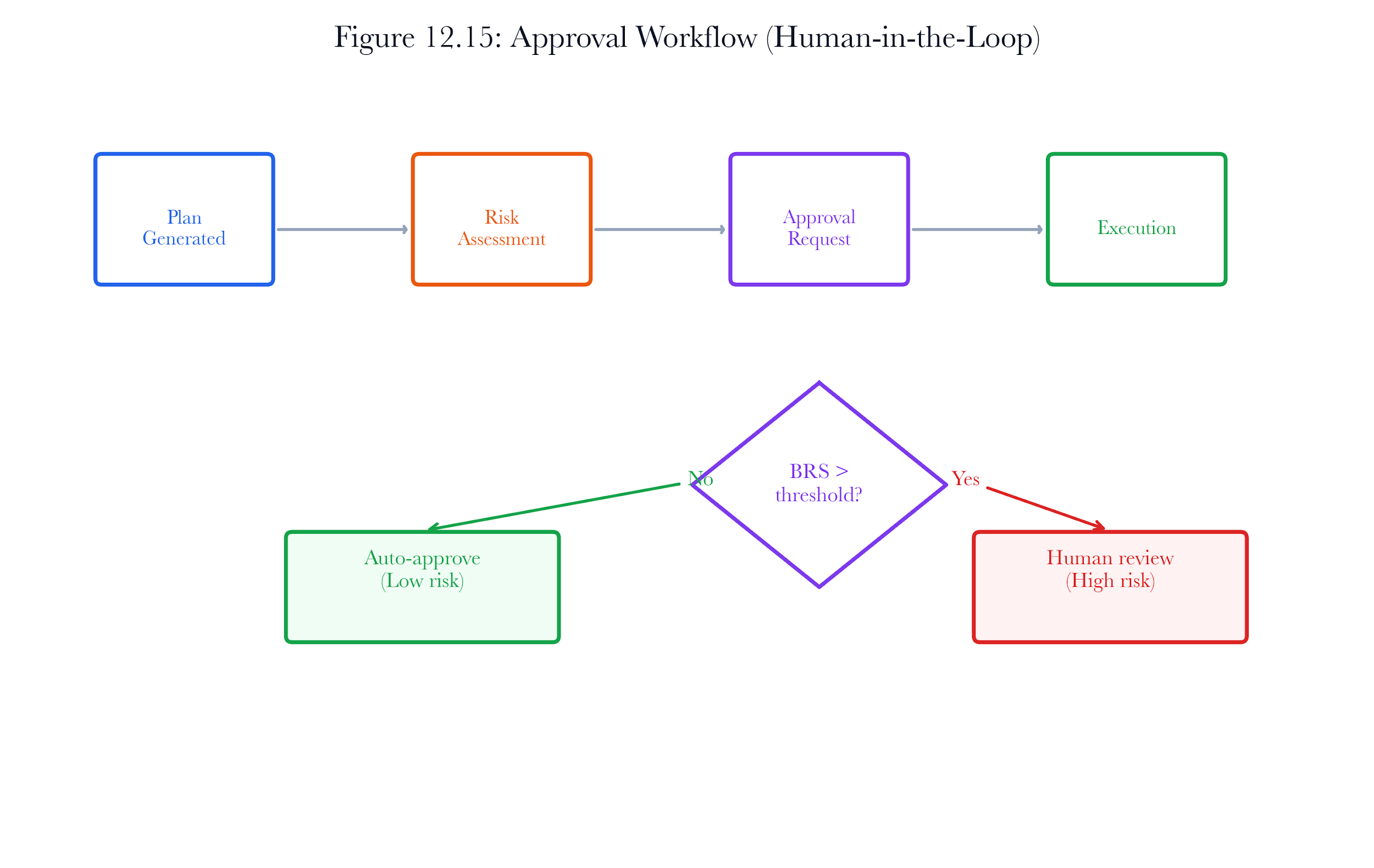
Figure 12.A7: ch12 fig15 approval workflow.
Figure note: The approval workflow belongs with the safety logic. It names where human authority enters high-consequence automation.
For approval as safety logic, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
The specific danger in approval as safety logic is false closure. The health contract may support one interpretation while the authority record points to another. The case must remain open until the rollback gate explains why the stronger claim is admissible or why it has been refused.
A senior answer for approval as safety logic produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts must agree on the same boundary. If they do not, the analyst has confused persuasion with proof.
Rollback must be prepared before execution and tied to health triggers.
Figure 12.A8: ch12 fig06 rollback checkpoint sequence.
Figure note: Rollback sequence belongs with first-class design. It lets students test whether recovery evidence is as strong as execution evidence.
For rollback as first-class design, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
The specific danger in rollback as first-class design is false closure. The health contract may support one interpretation while the authority record points to another. The case must remain open until the rollback gate explains why the stronger claim is admissible or why it has been refused.
A senior answer for rollback as first-class design produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts must agree on the same boundary. If they do not, the analytic has confused persuasion with proof.
A control mapping can say whether evidence exists. It cannot guarantee security.
For compliance-as-code without pretending, evidence quality is not evenly distributed. The airport operations center may provide a precise change action and still hide the condition that matters. That is why chapter-level mastery requires evidence boundaries, not vocabulary recall.
The review question is practical: where can an adversary make the system overconfident? The answer usually sits between safety simulation, rollback gate, and authority record. That gap is where expert students should work.
The section should end with an action. Quarantine, shadow-test, narrow the claim, collect one more artifact, or reject the conclusion. A vague recommendation is an analytic failure.
For compliance-as-code without pretense, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
The specific danger in compliance-as-code without pretending is false closure. The health contract may support one interpretation while the authority record points to another. The case must remain open until the rollback gate explains why the stronger claim is admissible or why it has been refused.
A senior answer for compliance-as-code without pretending produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts must agree on the same boundary. If they do not, the analyst has confused persuasion with proof.
Fixing the root cause can remove multiple symptoms. Fixing symptoms can leave the root cause live.
Causal remediation graphs should change how the analyst briefs risk. In the police evidence facility, leadership does not need a tour of the algorithm. They need to know which change action is admissible, which assumption is fragile, and which decision can be taken now.
The system should resist false closure. When safety simulation and authority record disagree, the correct state may be unresolved. That is a professional answer, provided the unresolved state has an owner, expiry, and next evidence request.
The highest-grade student will keep model behavior, governance, and mission consequence separate. Merging them into one confidence score destroys the audit trail that makes cyber analytics defensible.
For causal remediation graphs, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
The specific danger in causal remediation graphs is false closure. The health contract may support one interpretation while the authority record points to another. The case must remain open until the rollback gate explains why the stronger claim is admissible or why it has been refused.
A senior answer for causal remediation graphs produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts must agree on the same boundary. If they do not, the analytic has confused persuasion with proof.
Networks drift because people work. Self-healing should correct safe drift and escalate dangerous drift.
In the factory cell, self-healing and drift becomes a claim-control problem inside autonomous remediation. The analyst starts by naming the observed change action, the transformation that touched it, and the smallest defensible conclusion. Anything stronger has to wait for evidence.
The failure path is subtle. The dashboard consolidates safety simulation, rollback gate, and authority record into a single status. A senior reviewer should split them apart and preserve the disagreement as a first-class record.
The stop rule matters. The subsection should leave the reader able to say what blocks the claim, what promotes it, and what keeps it in review. That discipline is the difference between analytics and decorative scoring.
For self-healing and drift, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
The specific danger in self-healing and drift is false closure. The health contract may support one interpretation while the authority record points to another. The case must remain open until the rollback gate explains why the stronger claim is admissible or why it has been refused.
A senior answer for self-healing and drift produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts must agree on the same boundary. If they do not, the analyst has confused persuasion with proof.
The final artifact must prove what was planned, simulated, approved, executed, checked, and reversed.
Treat evidence packaging for auditors as an adversarial hearing, not a feature description. The municipal water site gives the system partial data, delayed data, and political pressure. The answer must still bind the change action to a named decision.
A strong implementation keeps the uncomfortable edge visible. If safety simulation says proceed while the authority record says wait, the system should not average the conflict into confidence. It should record the conflict and assign ownership.
The doctoral move is to ask for the counterfactual. What observation would make the original claim false? If the workflow cannot answer, it has built a belief engine rather than a cyber-analytic control.
For evidence packaging for auditors, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
The specific danger in evidence packaging for auditors is the risk of false closure. The health contract may support one interpretation while the authority record points to another. The case must remain open until the rollback gate explains why the stronger claim is admissible or why it has been refused.
A senior answer for evidence packaging for auditors produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts must agree on the same boundary. If they do not, the analyst has confused persuasion with proof. ate, execute low-risk changes, or execute with human approval.
The operational test for autonomy levels is whether a second expert can replay the reasoning. In a residential safety platform, this means the input record, transformation, exception handling, and decision authority must survive handoff.
The dangerous shortcut is to trust the most convenient signal. rollback gate may look stable while authority record carries the real warning. safety simulation may look mathematically clean while the mission context changes the cost of error.
A useful report should be modest and sharp. It should say what the analyst saw, what it inferred, what it refused to infer, and which collection step would move the case forward.
For autonomy levels, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
The specific danger in autonomy levels is the tendency toward false closure. The health contract may support one interpretation while the authority record points to another. The case must remain open until the rollback gate explains why the stronger claim is admissible or why it has been refused.
A senior answer for autonomy levels produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts must agree on the same boundary. If they do not, the analytic has confused persuasion with proof.
The course ends where dashboards stop. The question is what can be safely changed by Tuesday night.
In the last mile of cyber analytics, evidence quality is unevenly distributed. The regional hospital may provide a precise change action and still hide the condition that matters. That is why chapter-level mastery requires evidence boundaries, not vocabulary recall.
The review question is practical: where can an adversary make the system overconfident? The answer usually sits between safety simulation, rollback gate, and authority record. That gap is where expert students should work.
The section should end with an action. Quarantine, shadow-test, narrow the claim, collect one more artifact, or reject the conclusion. A vague recommendation is a failed analytic output.
For the last mile of cyber analytics, the review starts with the change action and ends only when the claim has a named owner. The analyst should state what the system observed, what transformation changed the record, and what conclusion is still forbidden.
The specific danger in the last mile of cyber analytics is the risk of false closure. The health contract may support one interpretation while the authority record points to another. The case must remain open until the rollback gate explains why the stronger claim is admissible or why it has been refused.
A senior answer for the last mile of cyber analytics produces three artifacts: a leadership sentence, a reproducible evidence note, and a hostile objection. The three artifacts must agree on the same boundary. If they do not, the analytic has confused persuasion with proof.
A student has mastered Chapter 12 when they can authorize autonomous remediation without confusing fast action with safe action. The answer must name the proposed change, affected asset, simulation result, authority tier, rollback command, health contract, and the post-action evidence.
Perturb the case with five remediation shocks: make one dependency hidden, make one maintenance window close early, make one rollback command untested, make one approval stale, and make one health check too weak to catch mission failure. The student should stop, stage, execute, or reject the action with a defensible reason.